To mesh or not to mesh
Understanding service mesh, and do you really need them?

Recently, i have been exploring the idea of a service mesh. But rohit, you just run a blog with maybe 2 users a month, why do YOU need a service mesh at all? Short answer?
FAFO.
Long answer, the itch in my brain won't let me be in peace unless I understand how all of the pieces fit together. Back in 2020, when I was working at an e-commerce giant, I was told to look at Istio logs during my on-call. I never really understood what it was back then, neither did I have the courage to ask after a certain time had passed. Few years later, I was in the same boat. But this time around, I had a better understanding of the fundamentals than before, so it was easier for me to really dig in.
The basic gist of a service mesh is, it makes your east-west traffic observable, secure and configurable. This allows you to have circuit breakers, retries, metrics, tracing, load balancing and more without touching your application code. Which means, your developers do not need to worry about the above things, as long as you have a devops-first culture in your organisation.
I used a lot of big words up there, let's go through them one by one.
East-West Traffic
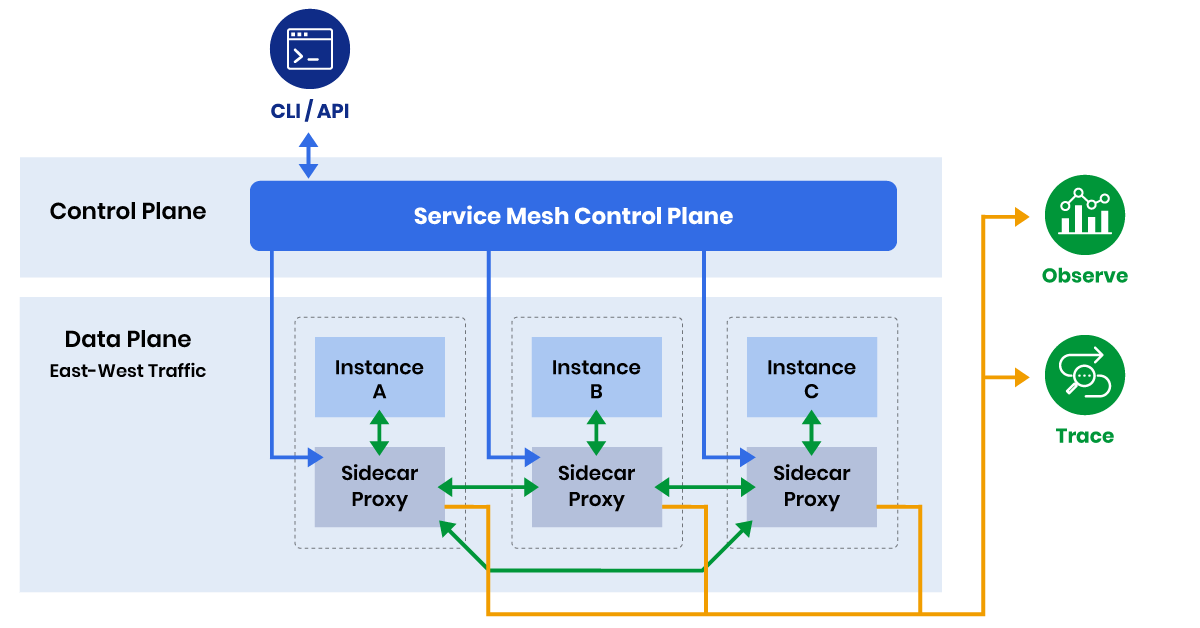
It basically means the traffic between the services in your cluster. For example, consider an e-commerce application. Your product description page needs a lot of information. It needs to talk with your reviews service, a product-detail service, a rating service, a coupon service and so on, you get the idea.
Now, how do you make sure the traffic between each of these services is observable, encrypted and can be configured to accept or reject inbound connections? Well, there are a lot of answers to this question, one of them is a service mesh. There are a lot of different service mesh options available, one of them and arguably the most popular one is Istio. Another option is Linkerd (I chose this).
Service Mesh Architecture Patterns
Before diving deeper, let's understand the two main architectural approaches to service meshes:
Sidecar-Based Architecture
Both Istio (traditional mode) and Linkerd work on the same principle: they deploy a sidecar container with your pods, which intercepts the inbound and outbound traffic using transparent proxying, applies the configuration you specify, and redirects to the application container. But here's the catch, these sidecar containers do add overhead, especially in the case of Istio. Istio uses something called an envoy-proxy as a sidecar container within each pod, which is a more resource-intensive proxy that intercepts all the traffic.
In case of Linkerd, it uses a Rust-based proxy, which is very lightweight in nature. So naturally, since I am running my own bare-metal cluster, I chose this.
Per-Node Proxy Architecture (Ambient Mode)
However, the landscape is changing. Istio introduced Ambient Mode in 2022 (now generally available as of 2024), which represents a significant shift from the traditional sidecar pattern to a per-node proxy architecture.
How Ambient Mode Works
Instead of deploying a sidecar with every pod, Ambient Mode uses:
- ztunnel (Zero Trust Tunnel): A per-node DaemonSet that handles L4 features like mTLS, telemetry, and basic traffic management
- waypoint proxies: Optional L7 proxies deployed only when advanced HTTP-based features are needed
This approach provides two layers:
- Secure Overlay (L4): All pods automatically get mTLS, basic telemetry, and L4 policies without any configuration
- L7 Processing: Deploy waypoint proxies only for workloads that need advanced HTTP routing, traffic splitting, etc.
Benefits of Per-Node Proxy Architecture
Resource Efficiency: Instead of running 100 Envoy sidecars for 100 pods, you run one ztunnel per node plus selective waypoint proxies. This dramatically reduces resource overhead, especially for clusters with many small services.
Simplified Operations: No need to restart application pods when updating the mesh infrastructure. The ztunnel and waypoint proxies can be updated independently.
Gradual Adoption: Applications get basic mesh benefits (mTLS, telemetry) immediately, with the option to add L7 features incrementally.
Better Resource Utilization: Shared infrastructure means better CPU and memory efficiency, especially important for resource-constrained environments.
Trade-offs of Per-Node Architecture
Network Hop: Traffic now goes through an additional network hop (pod → ztunnel → destination), which can add latency compared to sidecar's in-process interception.
Blast Radius: If a ztunnel fails, it affects all pods on that node, whereas sidecar failures are isolated to individual pods.
Debugging Complexity: Traffic flow is less obvious since the proxy isn't co-located with your application pod.
Alternative Service Mesh Solutions
While Istio and Linkerd dominate the conversation, there are other compelling options worth considering:
Cilium Service Mesh
Cilium takes a unique approach by leveraging eBPF (Extended Berkeley Packet Filter) to implement service mesh functionality directly in the Linux kernel.
How it works: Instead of userspace proxies, Cilium uses eBPF programs loaded into the kernel to handle traffic interception, load balancing, and security policies. This approach provides:
- Kernel-level efficiency: No userspace context switches for basic operations
- Integrated networking: Same solution handles CNI, network policies, and service mesh
- L7 visibility: eBPF can parse HTTP, gRPC, and other protocols without proxies
- Lower resource overhead: No sidecar containers or additional proxy processes
Trade-offs:
- Requires newer kernel versions (4.19+)
- Less mature ecosystem compared to Envoy-based solutions
- Complex debugging when eBPF programs misbehave
- Limited to what can be implemented efficiently in kernel space
Traefik Mesh
Traefik Mesh (now largely succeeded by Traefik Proxy's Kubernetes integration) was built around the popular Traefik reverse proxy.
Approach: Uses Traefik instances as both ingress controllers and service mesh proxies, providing a unified solution for north-south and east-west traffic.
Benefits:
- Familiar for teams already using Traefik
- Single solution for ingress and mesh
- Good integration with service discovery
- Simpler configuration for basic use cases
Limitations:
- Less feature-rich compared to Istio/Linkerd
- Smaller ecosystem and community
- Limited advanced traffic management features
Choosing Your Service Mesh Architecture
The choice between sidecar-based, per-node proxy, and kernel-based approaches depends on your specific requirements:
Use Sidecar-Based (Traditional Istio, Linkerd) When:
- You need the most mature ecosystem and features
- Fine-grained control and isolation are critical
- You're comfortable with the resource overhead
- Your applications require advanced L7 features consistently
Use Per-Node Proxy (Istio Ambient) When:
- Resource efficiency is a primary concern
- You have many small services that don't need L7 features
- You want gradual mesh adoption
- Operational simplicity is important
Use Kernel-Based (Cilium) When:
- Performance is critical and you can't afford proxy overhead
- You want unified networking and security
- You're comfortable with eBPF complexity
- You have modern kernel versions across your infrastructure
Mutual TLS
Another selling point of a service mesh is mutual TLS (mTLS). Rather than traditional TLS, where only the server has to prove its identity, both the client and the server have to prove their identity for the communication to happen. This provides encryption, authentication, and integrity verification out of the box with a service mesh.
In case of Linkerd, which I am using, there is a trust root certificate, which acts as the certificate authority, which in turn signs the intermediate certificate, and this intermediate certificate signs each workload certificate.
Interestingly, Istio's Ambient Mode provides mTLS by default for all communication without any configuration - as soon as you enable the secure overlay, all pod-to-pod traffic is automatically encrypted and authenticated.
So, do you need it? It depends. You need to ask yourself, am I running sensitive enough services which require encryption on a bare-metal cluster? I mentioned bare-metal, the reason being, a lot of cloud providers already handle north-south encryption for you via load balancers. So, if your only motivation for using a service-mesh was mTLS, you should first check if your cloud provider already supports this out of the box, and whether you really need pod-to-pod encryption.
Configurable
So, your backend needs to talk to your product detail service, which in-turn calls your coupons service, or your rating service, which calls your database and so on. But, what if you wanted to restrict inbound calls to your rating service, only from your product detail service?
Kubernetes with a CNI like Calico supports network policies, which solve these exact problems for you. But here's the catch, they operate on Layer 3 and 4 of the OSI model. Which means, you can control ingress and egress traffic based on ports, protocols etc., but not based on HTTP headers, since HTTP headers exist at Layer 7 (Application layer).
You might be thinking "doesn't Cilium offer Layer 7 based network policies?" And you are right, it does! Cilium can actually inspect HTTP headers and provide Layer 7 network policies, making it a viable alternative to service mesh for some use cases. But service meshes offer more advanced HTTP-based routing and traffic management beyond just network policies.
For example, if you wanted to do canary deployments, and route traffic to your canary pods using percentage-based splits, you can use a service mesh like Istio or Linkerd to distribute traffic between different versions of your services.
Since service meshes operate on Layer 7, you have access to these primitives, they give you greater flexibility and control over how your traffic flows between your services.
An example of simple canary deployments using weight-based traffic splitting:
# Istio VirtualService example
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: reviews-vs
spec:
hosts:
- reviews.default.svc.cluster.local
http:
- route:
- destination:
host: reviews.default.svc.cluster.local
subset: v1
weight: 90
- destination:
host: reviews.default.svc.cluster.local
subset: canary
weight: 10
Circuit breakers, load-balancing and retries
Another cool thing about a service mesh is, you can configure retries and circuit breaking. Let's dig in.
Retries are straight-forward, your services can retry failed calls automatically, based on your configuration. Service mesh can also handle load-balancing and circuit breaking for you out of the box.
Service meshes provide client-side load balancing, where the sidecar proxy selects a pod from a list of IPs provided by the mesh's control plane (e.g., Linkerd's control plane or Istio's Pilot). This allows advanced load balancing strategies like round-robin or least connections, alongside circuit breakers.
Circuit breakers work by monitoring the health of downstream services and "opening the circuit" when failure rates exceed configured thresholds. Once open, requests fail fast instead of waiting for timeouts, and the circuit gradually allows test requests through to check if the service has recovered.
Let's say service A is calling service B. If service B starts failing frequently, the circuit breaker in service A's proxy will open, protecting both services from cascading failures and giving service B time to recover.
It's pretty cool that all of this just works out of the box, and is completely platform agnostic.
Observability
The biggest selling point of a service mesh arguably is observability. In services with a lot of inbound and outbound traffic, you need to be able to see how traffic is flowing inside your cluster(s). You need real time metrics like RPM, success and error rates. Service mesh can do all of that and more for you.
Moreover, you can use something like Jaeger to export mesh logs to inspect them in real time. This gives you real time visibility inside your services, and can help you debug your services much more quickly if something goes wrong. This also gives you a clear picture of the traffic flow, and how to optimize your services based on the metrics available.
All of it sounds great, but are there any cons?
There are trade-offs with everything you bring into your architecture. For instance, each sidecar proxy adds resource overhead, which means you will be scaling and end up paying infrastructure cost. If the infrastructure cost is justified by the feature set you get, and you are going to be using the full feature-set of a service mesh, go for it.
However, newer approaches like Istio's Ambient Mode and Cilium's eBPF-based implementation significantly reduce this overhead, making service meshes more accessible for resource-constrained environments.
If not, you need to ask yourself: Am I doing this because everyone does it, or does my infrastructure really need the added complexity?
So, do you need a service mesh?
The honest answer is: it depends on your specific use case and architectural preferences.
You probably don't need a service mesh if:
- You're running a simple application with minimal inter-service communication
- Network policies and API gateways meet your current needs
- Resource efficiency is critical and you can't justify the overhead
- Your team lacks the operational expertise to manage the added complexity
You should consider a service mesh if:
- You're dealing with complex microservices architectures
- You need advanced traffic management (canary deployments, circuit breakers, retries)
- Comprehensive observability is critical for your operations
- You require mTLS for security compliance
- You want to standardize cross-cutting concerns across your platform
Consider the modern alternatives:
- Istio Ambient Mode if you want mesh benefits with lower resource overhead
- Cilium Service Mesh if you prioritize performance and can handle eBPF complexity
- Hybrid approaches where you use network policies for basic needs and selective service mesh features for advanced use cases
For my personal cluster? It's probably overkill, but that's exactly why I'm doing it - to learn, experiment, and understand the full picture. Sometimes the best way to learn is to build something you don't strictly need, just to see how all the pieces fit together.
The service mesh landscape is evolving rapidly. The traditional sidecar-heavy approach is being challenged by more efficient architectures, and the choice is no longer just "mesh or no mesh" - it's about finding the right balance of features, performance, and operational complexity for your specific context.
After all, that's what this whole journey is about - understanding the tools and technologies that power modern infrastructure, even if you don't need them for your current scale.